I have drafts of a couple of posts on accessibility topics that I haven’t been able to finish because they got too complicated. Not because the subject matter was particularly complex, but because they required the reader to start with knowledge of a particular framework.
The W3C has defined what to do for accessibility at each ‘end’ (i.e. client side or web site site), but there is quite a lot of overlap, and scant advice on who should be responsible for what.
I’m going to try and show who’s responsible now, and where things should go.
Note: As a base assumption, I take ‘web accessibility’ in the stricter sense of ensuring that people are able to use web sites, regardless of their (dis)ability.
W3C model
The W3C, with responsibility for shepherding web technologies along a useful path, long ago outlined how things should fit together. Their essential components of accessibility include the User Agent Guidelines for browsers and assistive technologies, the Authoring tool guidelines for Content Management Systems and other tools, and the Web Content Guidelines for developers and site owners.
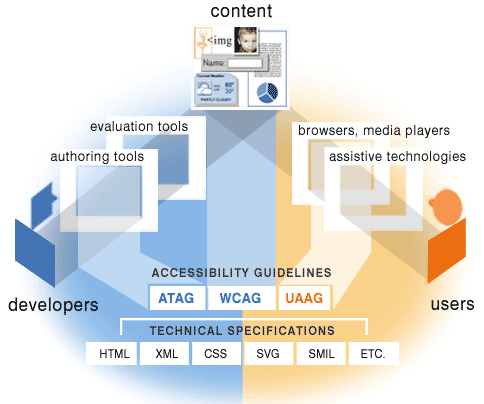
However, in the late 90’s when these guidelines were being developed, they were already starting from a very imperfect place. The accessibility of most sites, tools and browsers were appalling. You probably remember that there are many guidelines that start: “Until user agents” can do this that or the other. The developer wasn’t allowed to use pop-ups, client side redirects, or blinking text (amongst other things).
The next version of the guidelines has tried to avoid this, but it’s interesting that several of the things that they assumed would be fixed at the user-agent end, haven’t been (e.g. allow users to control flickering
).
There is no getting away from the fact that you must have standards (or guidelines in W3C speak) for how the various web technologies interact. There are simply too many user-agents for developers to test against. The popular browsers are hard enough to deal with, without the dozens of screen readers, magnifiers, keyboards, voice recognition and other technologies that all create a different experience of a web site.
As Mike Davies said, there has to be trust on each side that the other will perform in an expected way. For progress, you need mutually developed standards, as the WHATWG has demonstrated recently by actually making process in advancing HTML.
The usability gap
Currently, the weight of responsibility for accessibility falls on web site owners, and by proxy, web developers. This is actually harmful for the accessibility of the web in the long term, as it stifles progression.
 An obvious example is text-size widgets, a feature on a site that allows the user to change the font-size of the text. In the W3C model, this is superfluous, the user should be able to re-size the text from their browser. In web site accessibility terms, it’s like a spoiler on a Robin Reliant, unnecessary and in effect useless.
An obvious example is text-size widgets, a feature on a site that allows the user to change the font-size of the text. In the W3C model, this is superfluous, the user should be able to re-size the text from their browser. In web site accessibility terms, it’s like a spoiler on a Robin Reliant, unnecessary and in effect useless.
However, there is a usability gap at the moment.
You can argue that a text-size widget increases the accessibility of the site because people don’t know that they can increase the text size in their browser. And, in general, people don’t. There are many things that user’s can do to any site (built reasonably well with HTML & CSS), from re-sizing the text to changing or removing the layout, or even applying their own colour scheme. Given the multitude of abilities and preferences there are, this is the only way to have a hope of catering for everyone.
But so few people know how to adapt their user-agents that an impartial observer could conclude that it is reasonable for the site to be responsible these aspects.
But that doesn’t make it the right approach to the problem, and in this case the problem is cross-site applicability.
Best for users across all sites
 I’ve spoken before about the limiting business models of certain products. If a site with a particularly enthusiastic developer, or a shed load of cash invests in something that improves the experience of the site for a certain population, that’s great, but should others have to?
I’ve spoken before about the limiting business models of certain products. If a site with a particularly enthusiastic developer, or a shed load of cash invests in something that improves the experience of the site for a certain population, that’s great, but should others have to?
If users like a feature on one site because the site becomes easier to read or use, they will miss it (and ask for it) on other sites. But they won’t get it on all other sites, whether it’s because other site owners can’t afford it, don’t care, or for other reasons. It’s not scalable.
There are some things that the site owner (and by extension the developer) has to be responsible for, such as the content, and the technology used to create the site.
Some things the user (and their technology) have to be responsible for, such as rendering the content according to the standards, and knowing that you can click links to navigate. (Yes, this used to be an issue in usability testing a few years ago!)
There are a couple of views that tend to highlight where people think this balance should lie. I’m highlighting extreme versions of these views:
- Technical view of accessibility
- If it works in Lynx (a text browser) it must be accessible.
- User’s view of accessibility
- If something doesn’t work for everyone (e.g. the
titleattribute), you shouldn’t use it.
Neither is ‘right’, but going back to my base assumption, you have to consider what accessibility is.
Accessibility = usability
A common theme, but if you are familiar with the definition of usability, accessibility fits right in. Usability is:
the extent to which a product can be used by specified users to achieve specified goals with effectiveness, efficiency and satisfaction in a specified context of use.
In web accessibility, the product is the web site, “specified users” are people with disabilities, and the “specified context of use” encompasses their task, knowledge, technology, and ability. Whether you think this is too all-encompassing a definition or not, the bottom line is that a real accessibility issue is when a person (with a disability) can’t use your site, not necessarily that a certain technology can’t.
What makes accessibility complex is that different technologies give the person a different view of the same site. That’s what intrigued me in the first place. There are so many contributing factors at play, from the end-user, their technology (and whether they know how to use it), what the site does, and how that site is produced.
This makes it very difficult to say whether an issue a person has should be fixed by the site, the tools that made the site, the browser/assistive technology, or that the user needs educating. Usability is rarely clear cut, humans are messy and it’s probably better to either create a standard that can work for all, or accept the current situation.
Analysing the gaps
Site responsibilities
Working from WCAG 1 & general web standards, these are squarely in the domain of the site. These cannot (usually) be worked around on the user-agent end:
- Text equivalents.
- Using clear language.
- Separation of content, presentation and behaviour.
- Proper use of semantic elements.
- The site works without client-side scripting.
- Ensure that non-HTML formats are accessible (JavaScript, Flash, PDF, multimedia etc. Note on other formats.)
- Identifying the natural language (and changes to it).
- Using valid code.
- Ensure information conveyed with colour is also available via markup or content.
- Clearly identifying links.
- Consistent and understandable layout and navigation.
- Correct use of labels in forms.
- Ensure images with text have sufficient contrast.
- Specifying the expansion of abbreviations.
- Keywords first for headings and links.
- Supplementing text with graphical or auditory presentations.
I’ve put together a list of categorised WCAG 1 checkpoints if you really want the details. I was surprised by how many don’t come up any more.
User / User Agent responsibility’s
These could be adjusted by the user, although some are currently very difficult to do via a normal browser:
- Prevent the screen from flickering/blinking.
- Expand / contract font size and layout.
- Prevent redirects, refreshes and pop-ups.
- Skip over sets of links.
- Access to useful DOM elements (e.g.
titleandciteattributes). - Navigating pages via DOM elements (e.g. Scanning headings)
Filling the gaps
There are really two main gaps, each with a technology and knowledge component. The tech components are that the:
- Tools to create web sites don’t produce accessible code easily.
- User agents don’t allow people to customise their experience easily.
The knowledge component of each is that:
- People don’t know to buy better tools.
- People don’t know to try better browsers/user agents.
So who’s responsible?
I’m afraid I’m not going to answer that for another two posts yet. In the next post, I’m going to examine the user-agent issues, and see how they could be improved. After that, there is the practical “how do people implement these sites” (the authoring tools).
However, I’m fairly sure that it’s going to be a path. If a site implements something that should be on the user-agent end, it should do so in such as way as to pave the way for user-agents to take over.
Technorati Tags:
i’m intrigued…can’t wait for the next two episodes, as you well know that this is right up my street.
As usual a cracking article.
I will definitely be ‘tuning in’ for the next few episodes. I just spent the last few days at “Access U” really trying to figure out the best way to introduce accessibility into our design and development processes. One of the sessions claimed that the tasks associated with accessibility rested between content authors, testers and management, and another advocated addressing it as a QA issue, above all else. I will be interested to learn your thoughts..
Hi Andrea, you might find my accessibility lifecyle article better for that purpose (i.e. the developer end of things). The next one is how user-agents can be improved, and the final one will be on tools.