Floating ideas onto the CSS working group can be a frustrating experience, possibly almost as frustrating as seeing the same questions come up every few months! I think I may have made a mistake in terms of asking about this idea, by doing so within a thread about parent selectors.
Empty vs text-only
My original question was about how to differentiate a link that contains an image and a link that contains only text.
The scenario I had come across was identifying external links with this CSS 2.1 selector:
a[href^="http"] {...}That CSS matches external links with have an href attribute that starts with http, but not internal links that have a path to the file, e.g. /folder/file.html.
I used that to add a small background image to external links as a visual hint that the link goes to another site. You can see this example on a news item on the UK Windsurfing site.
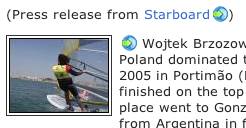
That worked fine (in Firefox, Safari & Opera), but as you can see it is applied to image-links as well as text links. That can lead to some strange effects if the image is floated (links given a red border):

There are several logical ways you might think you could select links that only contain text. For example, to apply the styles when:
- the link contains only text.
- the link does not contain an image.
- the link does not contain any other elements.
You can apply the style to an image within a link (e.g. a[href^="http"] img {...}), but that is the exact opposite of what I want to do, which is only apply it to text links.
Unfortunately there does not seem to be a way to differentiate links based on what they contain.
Going up the tree
An inherent limitation of CSS selectors is that they cannot go ‘up’ the DOM tree. It is an often asked question on the www-style list since at least 1999, the last one I noted was this parent selector thread.
One of (if not the) main reason for the parent selector to be rejected is due to it creating performance issues. I can understand that, programmatically the browser would have to know every child element before it could start styling the parent. Boris Zbarsky stated previously on this topic:
Now consider parent/predecessor selectors in all their forms (:matches, parent combinators, etc). Let’s take the parent combinator as a simple to analyze example. The condition for correctness on insertion in this case is: “If a node is inserted, and any node anywhere in the document matches the sequence of simple selectors on the left of a parent combinator, style needs to be recomputed on all nodes in the document.” No comment on pageload performance.
I understand that (in a vague kind of way), and trust the source (someone who fixed one of the few bugs I found in Gecko!).
Unfortunately I seem to have gotten the text-node idea caught up with this selector that would not be good to implement.
Identifying text-only nodes
I haven’t been able to find any other (CSS) methods to get the styling I would like, as you cannot style text within a link, so the link is the only element that will take the styling. If you open up the DOM inspector to see what you have to work with, you can see that there are text nodes:
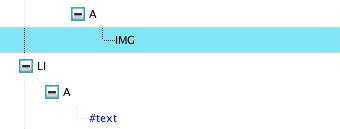
The :empty pseudo-selector is almost what I need, but it doesn’t apply when there is text within the element.
I would propose a “text-node” or “text-only” pseudo class, so that this:
a:text-only {...}
Would apply to this:
<a href="#">link</a>
But not this:
<a href="#"><img src="#" alt="text" /></a>
Or this:
<a href="#">some <strong>other</strong> text</a>
Then all you would need to add styles to a text link to another site is: a[href^="http"]:text-only
The performance issues mean that the parent selector is unlikely to be implemented any time soon, which is the generalised version of what I would like. However, I don’t see the same issue with this, it is something JavaScript has access to, but not CSS.
Unfortunately no one has replied to this either time I asked (1, 2).
It is quite frustrating, I’d actually rather get shot down than just silence. For the sake of the long term members and newbies alike, I’d suggest that the W3C make a start on Eric Meyer’s suggestions for Working Group Outreach, a short-term item might be a www-style FAQ of common issues.
Technorati Tags:
I was hoping to find the exact same thing… Now at least I know it’s not possible :(.
Wait… I got it!
😀
#contents a *:not(img) {
color:black;
text-decoration:none;
border: 1px dotted #ccc;
}
From my reading of the current Negation sector spec (updated since this article), this:
a *:not(img)Would select any element inside a link that isn’t an image. Which might work in your circumstances (e.g. if you have a
strongelement inside the link), but not for me, because there is no other element inside the link, it’s just text.Therefore this won’t be selected by your selector:
<a href='page.html'>example<a>Conceptually, what we need is a variation of
E:emptythat is for text nodes, e.g.E:textorE:no-children.I would argue that a pseudo class isn’t the answer, as we are looking to select a node type in its own right, and which would then have its own set of pseudo classes. What is needed is something more akin to the asterisk; pick a symbol that’s not used yet, say ‘+’. Then you can pick out the text node(s) within an element independently from images, etc., allowing (for instance):
a > +:first-child { ... }Hi Simon,
I don’t think that would work, I’m trying to select the ‘a’ element based on it’s contents, not selecting the contents.
What you suggest would mean you’re styling the contents, and that you would need an element within it (not just text).
I’ve just run into this; wanting to back up the tree, whilst trying to figure out how to make expanding and contracting navigation without Javascript. Focus springs to mind but with a:focus the focus is triggered in an inconvenient place when it comes to cascading, my a doesn’t contain the sub nav’s but my li which lives above the a does. DOM is the only way.
But the CSS is hiding the sub nav items when the page loads so it should be able to traverse backwards from the A:focus to the LI sort of like:
li << a:focus ul { display : block;}
This could say: Pass the focus from the a and re-cascade from the li downwards, even reading it as a human that makes sense as the direction is clearly shown.
Anyway without getting confused, cascading backwards while being really useful for navigation systems, is another buzzword or phrase to wow our peers with. “Have you tried the reverse cascade trick?”. If only we could do it for nav systems it would free use from JS.
here from your early comment at the css3 standards suggest page. caveat: i am not a web type guy, so haven’t followed much of the grotti obscuratia.
I have exactly the same desire as you for usercontent control of “text-node”
but in light of the ever-desired parent selector, wouldn’t you also want to textnode style your inner=tag example: <a href=”#”>some <strong>other</strong> text</a>
??
if you don’t want your inner <strong> to take on the textnode style, you can restyle it via accepted child selector:
a>strong {blahhh:blahh;}
[now hoping the this comment thingie takes encoding etc as intended]
Not will work, or just apply a server side technology to mark the needed classes. Or place the A highlight first and then override it for specific elements such as img.
To the person who said + isnt yet used: its used for sibling selections.
Hi… I’m no CSS expert here, but I do have a suggestion. I noticed that when I blog using wordpress, the images I add do not have a target option. (‘_blank’, ‘_self’, ‘_top’ or ‘_parent’). For my usual text links, I always set it that it opens in a new window and therefore, I see ‘_blank’ in the link tag.
Looks like this:
<a href=”#” rel=”nofollow”>Text</a>
So maybe you could use this:
a[target=’_blank’] {}
I know it doesn’t solve the problem, but it’s good enough for me anyway.
🙂
I’d rather not open links in a new window (and definitely not without warning the user – see WCAG).
Also, you would still can’t automatically mark text-only links, you would be doing that manually.