After my initial disappointment with the Office 2007 plug-in for creating PDFs, I’ve had some discussion with the Microsoft team, and a chance to do a bit more testing. This post compares the conversion of a simple Word 2007 document with the Office plug-in, Acrobat 8.1, and OpenOffice.
I have to thank Jeff Bell and Cheri Ekholm of the Microsoft Office team, they kindly answered my many pestering questions, and took time to look into the issues I was having.
The Source
I created a simple document using Word 2007, using it’s default font (Cambria), and the default styles. Into this document I added a title, some lists, a few paragraphs, an image (with alt), a quote, a two column section, and a table (with headings). I’ve put all the documents in a zip file (650k) if anyone else wants to test them as well.
Basic stuff, but everything was correct for making an accessible PDF, i.e. using the native style structures in Word.
The conversion settings
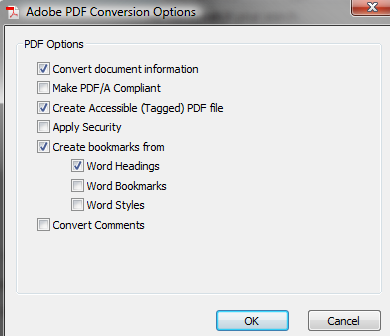
I used the defaults for each method, making sure that it was creating a tagged PDF. These are the settings in the office plug-in:

These are the options from Acrobat 8.1:
The results
Both Acrobat and Office produce a decent document that appears the same as the original, and is tagged. However, there are some differences.
File size
The Acrobat version was 148KB, the Office one is 424KB. For such a simple document (with default fonts) I was quite surprised, apparently it’s due to more information being embedded, which is obvious in small documents, less so in larger documents.
Tags
There were some immediate differences, although mostly it was subtle differences like Acrobat using <Heading 2> and Office using <H2>.
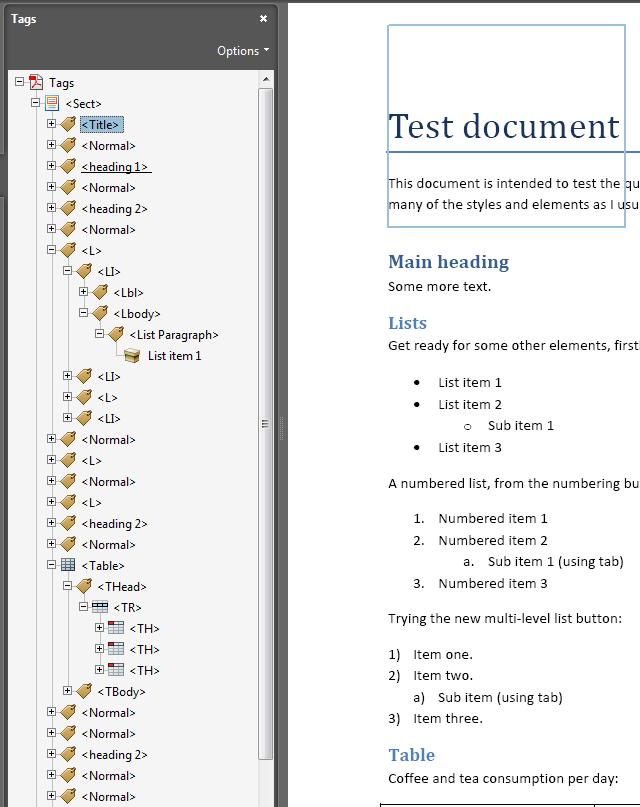
The best way to assess the tags is to view them in Acrobat Pro, here are a couple of snapshots, you’ll probably want to open them in new windows or tabs:
Created with Acrobat
Created with Office 2007 PDF plug-in
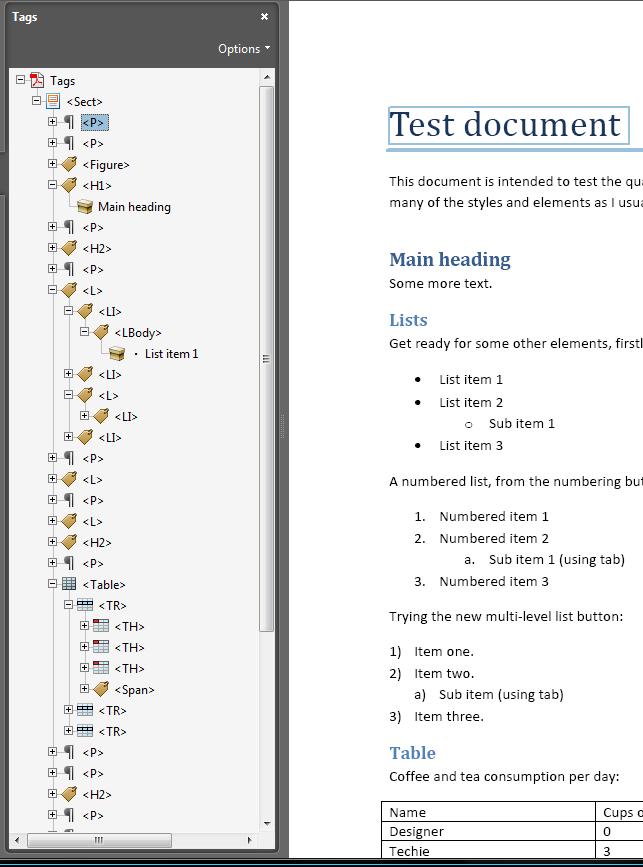
The main problem found was in Office, where the tag for the image was mysteriously placed immediately after the second paragraph, instead of on the second page. This is likely to be a bug.
The second issue was that the quote style in Word didn’t translate to a quote tag. Apparently, this is because Office uses the underlying styles, not the style name shown when editing. For example, this is the modify style dialogue for the Title style:
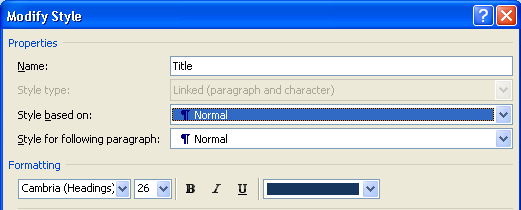
This method creates two issues in this document:
- The Title style came across as a paragraph.
- The Quote style came across as a paragraph.
If a style isn’t in the styles set, you can’t create a template that will automatically produce the right tag in the PDF. Comparing the styles list against the PDF tag list, there are quite a few missing (e.g. article, link, reference). However, I’m not actually sure how important that is, at least for now, as current screen readers don’t make use of ‘rare’ elements yet.
Acrobat uses the style names, rather than the style they are based on, so whatever you call each style will become the tag. That is why you get <Heading 2> rather than <H2>.
I sent the documents to a friend (Léonie Watson) for a ‘blind’ test (in both senses, she didn’t know what created each PDF), using current versions of JAWs and Acrobat. Most of the tags were fine in both, so both versions of the headings ‘work’, even though the Office method matches the PDF standard set better. The Acrobat version seems to put the bullet points on separate lines (in the tags, therefore for screen readers), which is strange when reading.
What it does mean is that the default styles will not create what you think they do when using the Office plug-in. This makes it extra effort to set up a template for creating accessible PDFs.
Other accessibility features
The read out loud function works equally well for both – no problem there. Changing the colour scheme also worked well for both.
Document re-flow
This was not the same. In a previous document (from the last article) reflow had removed the text (due to a font issue). For the Office created PDF test document, reflow doesn’t actually work at all, the option is grayed out:
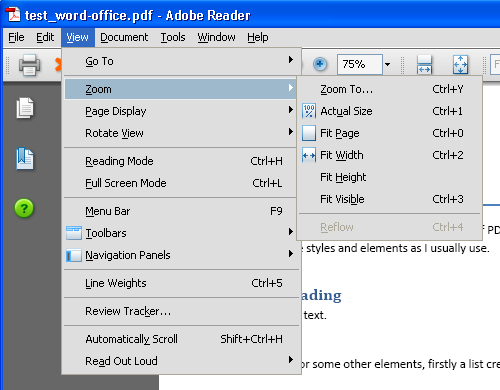
I can’t tell why this is, I don’t know of another PDF reader that offers the function, and the spec is, well, long, and I haven’t read it yet. It might be that the Office plug-in doesn’t do something, or it might be the Acrobat reader isn’t accepting the input as it should.
OpenOffice
OpenOffice is the poor cousin in terms of creating accessible PDFs, you’d have to do quite a lot of Work (in Acrobat Pro) to overcome the issues for each document:
Open Office (at least from version 2.4) can export a tagged PDF, and when creating from within OpenOffice (rather than importing a Word file) the headings, lists and alt text all come through fine. Changing colours and reflow (with the exception of the image being dropped to the bottom) also work fine. (Thanks to David for the update).
Just be careful to tick the ‘tagged PDF’ option, as it is not on by default.
Also be careful when importing from Word documents, as the following problems were found with this method:
- The Alt text was not included.
- Headings were brought through as paragraphs (even though they were OpenOffice headings).
- Lists items were not nested in the list (i.e. the second item was not in the list).
- The Quote was not brought through as a quote.
Overall
Overall, the Word & Acrobat combination provides the most effective workflow for creating accessible PDFs. With a good template set up, or even using the default styles, it’s pretty much fire and forget (assuming the document includes everything it needs).
However, it’s worth remembering two things about the Office 2007 plug-in:
- It’s a version 1 program.
- It’s free.
The first means that it could be updated in future to iron out the bugs (notably the re-flow issue, as you can’t get around that).
The second means that it might be more effective for an organisation to use the Office plug-in, and have a couple of people with Acrobat Pro to sort out the few accessibility issues. We haven’t quite been relieved of the Adobe accessible PDF tax yet, but it’s a step in the right direction.
Appendix: Other Office programs
Cherie Ekholm from the MS team described a little about how tagging with the plug-in varies depending on the program. Word, PowerPoint and Publisher have extensive tagging. (NB: I don’t think Acrobat supports Publisher, at least not well in the testing I’ve done).
Visio, Access, OneNote and Excel have much more limited tagging, but all do give users the opportunity to add alt text for images. I think Excel is the only disappointment there, the others have never benefited from good tagging support. I can’t imagine how you would usefully tag Visio, but I’ll have a look later.
The Excel functionality was described this way:
while Excel does some tagging of
<TR>and<TD>with the Office plug-in, it doesn’t do it well unless you use the new tables feature in 2007 for the data you want to tag. Because there is no mechanism to mark the header row in an Excel table or in the spreadsheet itself, there is no tagging for<TH>. Word is currently the only Office application that has the ability to identify table headers. As a user, the Excel behavior doesn’t make sense to me because most spreadsheets look like they are a type of table (whether you apply the new table feature or not). But Excel spreadsheets are not tables unless you use the new feature.
The important thing is that it’s possible to structure the PDF from the base document, before the PDF process is started. Then the next most important aspect of creating accessible PDFs is that it’s easy, default, or possible to enforce the accessible practices in the base document.
So we now have step one.
Hah, the perennial coffee consumption table as an example. It’s becoming as ubiquitous as “foo” and “bar” for replaceable text! 🙂
Surely the word is “plugin” or “plug-in”? “Pluggin” looks like a non-punctuated “pluggin'” to me.
The
<code>samples in the block quotation are pretty much invisible to me. You could probably make it white and let the monospace font type indicate it as code. Or maybe use a paler orange so it has contrast against that dark blue background?Anyway, another informative article. The screenshots are a big help in understanding the topic, imho. Although I had to view them in a new tab to really see the detail.
The key point is still using the native Word styling structures for the original document?
Thanks Ben,
Yep, I’d never looked it up, but having done so I think plug-in is probably the ‘correct’ term, updated now.
You’re also right about the code samples in the quote, I haven’t used that before and hadn’t noticed the contrast. I’ve updated that, I still need to sort out links in quotes though. It was easy using the Colour Contrast Visualiser 🙂
Also added a note that you might want to open the screen shots in new windows/tabs, although the choice is the user’s.
And yes, the underlying structure in Word is used to create the structure in PDFs. Have a look at my accessible word section from a previous article for more on that.
NB for everyone else: The main document has been updated based on Ben’s comments.
Hx and Headingx and Heading x are treated as functionally identical and will be actually identical in the PDF/UA spec. I know, because I wrote the headings section.
List bullets are not automatically generated by the rendering agent as they are in Word or a browser. They have to be encoded in there somewhere. Poorly, apparently.
Thanks for that Joe, it would be nice to be able to read the spec…
I have used openoffice to create tagged pdf, and have had no problems with headings. I’ve just run a few tests to check this using the latest version 2.2.1. If I create a document within writer and export to tagged pdf, then the headings are ok. If I save your test_word.odt to word xp format, open it in writer, export to tagged pdf, then the headings are again ok. If I directly export your test_word.odt to tagged pdf, then the headings are translated to paragraphs. Did you create test_word.odt by importing test_word.docx into writer?
The problem with “save as pdf” from office is the bookmarks. it’s generated, but compared to acrobat conversion (the button in word 2003, acrobat professional 7 or 8), the numerotation is lost
we like thoses numbers in the bookmark, in business, thoses numbers are referenced often
so how can i in office 2007, use the button acrobat was giving me in office 2003? to keep my bookmarks numbers for all titles and figures?
The problem with “save as pdf” from office is the bookmarks.:
Exactly. The biggest problem is that when you encrypt your PDF in Acrobat 7/8, bookmarks are lost at all.
Alastair, you should also know about the role map. What Joe describes is accurate about H2 and Heading 2 being equivalent, but it is only necessary for these to be regarded as equivalent by reader when the application doesn’t create a role map.
What the role map does is take the tag names (and the spec says that you can use any name you want for tags) and associate them with known and expected roles. This may not be needed for simple documents where the author accepts Heading 1 as the top style name, but if you have a long list of styles you may have different style names for headings at a particular level depending on where they exist in the document (e.g. heading 2’s in the table of contents may have style name heading2_toc and heading 2’s in the body may be heading2, but both need to be semantic elements).
If the role map is created by the app publishing the PDF, heading2 and heading2_toc are both mapped this same role and interpreted correctly by Reader.
This is also important for people with localized versions of Word – in German the heading style name may be “Überschrift 2” and the role map is needed to handle this translation.
Thanks for that Andrew. I did discover the role map not long after writing this article. It was one of those things where you wonder how you hadn’t seen it before! (“Was it really in previous versions? Yea, damn!”)
However, the chances of Joe Public (rather than Clark) using it are pretty remote, so I think it’s valid to compare the default output of different mechanisms.
Alastair, I agree that the role map is not likely to be used by most end users, but then the same can be said about the tag tree also.
The point is that the role mapping needs to be part of the default output from different applications, not that users need to mess around with it.
If the role map is used, the discussion about tag names becomes irrelevant, so if you are looking at a PDF file and see tag names that aaa, bbb, and ccc you don’t know if this is an issue until you either check the role map to see if these tags are mapped to known roles or test with a screen reader that is known to support the roles that you believe are used.
Ultimately what matters is not the tag name, but how it works for the end user, but it is important for people who are inclined to dig into a PDF to repair it to understand what role map does.
That is definitely the key factor, if people do the right thing (i.e. use structured content) in the source application, they shouldn’t have to worry about tags or role maps.
So what’s the process of making sure that works in different apps? It’s been done with Word, and to some extent other MS office applications, but how about other applications?
It’s a responsibility that kinda falls between the PDF creator (e.g. Adobe) and the people behind the source application.
Hi Alastair,
I wanted to make you aware of the work that NetCentric Technologies (net-centric.com) has been doing in this area. We specialize in developing products that test for PDF accessibility and remediate accessibility problems in PDF documents. A couple of things may be of particular interest to you:
1) We are about to release (in January 2008) a beta version of our office add-in product (called PAW) that generates Section 508-compliant PDF’s from Word documents, including correct tagging of tables and other objects (our VP of Product Development, Ferass ElRayes, is heavily involved with PDF/UA and has co-written the chapter on tables). If you are interested in taking a look at this beta product I can put you on our beta list.
2) We have a unique product called CommonLook for Adobe Acrobat which is the currently the leading product in testing for S508 compliance and remediating PDF documents for Section 508 accessibility. Let me know if you would like to take a look at this product as well.
Happy holidays and best wishes for 2008.
Regards,
Monir ElRayes
President
NetCentric Technologies
Hi David, sorry for taking so long to follow up on this – you are right. At least with the new version 2.4.
Open office on OSX isn’t a particularly great experience (it isn’t consistent with the rest of the system), I had been using an older version of Neo office instead.
I installed 2.4, created a new test doc rather than importing from a Word doc, and the headings, lists, and alt text all exported to PDF fine.
I’ll update the article to reflect that, thanks David.
As I see some of the comments here are actually fairly recent, I figure I’ll contribute my two cents to them.
Recently, I downloaded the conversion plugin for Word 2k7 and attempted to convert a rather lengthy document to PDF format. Much to my dismay, creating bookmarks similar to those I see used so frequently in other PDFs I’ve come across is a process that is, to say the least, disappointing from a formatting perspective – and for seemingly no reason.
I’m merely thinking “aloud” here, but what would be nice is if the Word plugin actually provided a method of allowing the user to create tiered bookmarks under sorted, expandable headings. This would make navigation of the document much more accessible to those it’s distributed to.
I also speculate it would be helpful if it allowed the user to assign a title to the bookmark that contains spaces, since Word does not seem to like allowing that normally.
Having these issues resolved would certainly satisfy my only real complaints about the Word 2k7 PDF conversion plugin.
As an aside, I’m still rather amazed that a 1-page PDF created by Word borders on 300 pages of code when opened in Word after creation.
That’s all I have to add.